EfficientNet与ResNeXt101_wsl系列¶
概述¶
EfficientNet是Google于2019年发布的一个基于NAS的轻量级网络,其中EfficientNetB7刷新了当时ImageNet-1k的分类准确率。在该文章中,作者指出,传统的提升神经网络性能的方法主要是从网络的宽度、网络的深度、以及输入图片的分辨率入手,但是作者通过实验发现,平衡这三个维度对精度和效率的提升至关重要,于是,作者通过一系列的实验中总结出了如何同时平衡这三个维度的放缩,与此同时,基于这种放缩方法,作者在EfficientNet_B0的基础上,构建了EfficientNet系列中B1-B7共7个网络,并在同样FLOPS与参数量的情况下,精度达到了state-of-the-art的效果。
ResNeXt是facebook于2016年提出的一种对ResNet的改进版网络。在2019年,facebook通过弱监督学习研究了该系列网络在ImageNet上的精度上限,为了区别之前的ResNeXt网络,该系列网络的后缀为wsl,其中wsl是弱监督学习(weakly-supervised-learning)的简称。为了能有更强的特征提取能力,研究者将其网络宽度进一步放大,其中最大的ResNeXt101_32x48d_wsl拥有8亿个参数,将其在9.4亿的弱标签图片下训练并在ImageNet-1k上做finetune,最终在ImageNet-1k的top-1达到了85.4%,这也是迄今为止在ImageNet-1k的数据集上以224x224的分辨率下精度最高的网络。Fix-ResNeXt中,作者使用了更大的图像分辨率,针对训练图片和验证图片数据预处理不一致的情况下做了专门的Fix策略,并使得ResNeXt101_32x48d_wsl拥有了更高的精度,由于其用到了Fix策略,故命名为Fix-ResNeXt101_32x48d_wsl。
该系列模型的FLOPS、参数量以及T4 GPU上的预测耗时如下图所示。
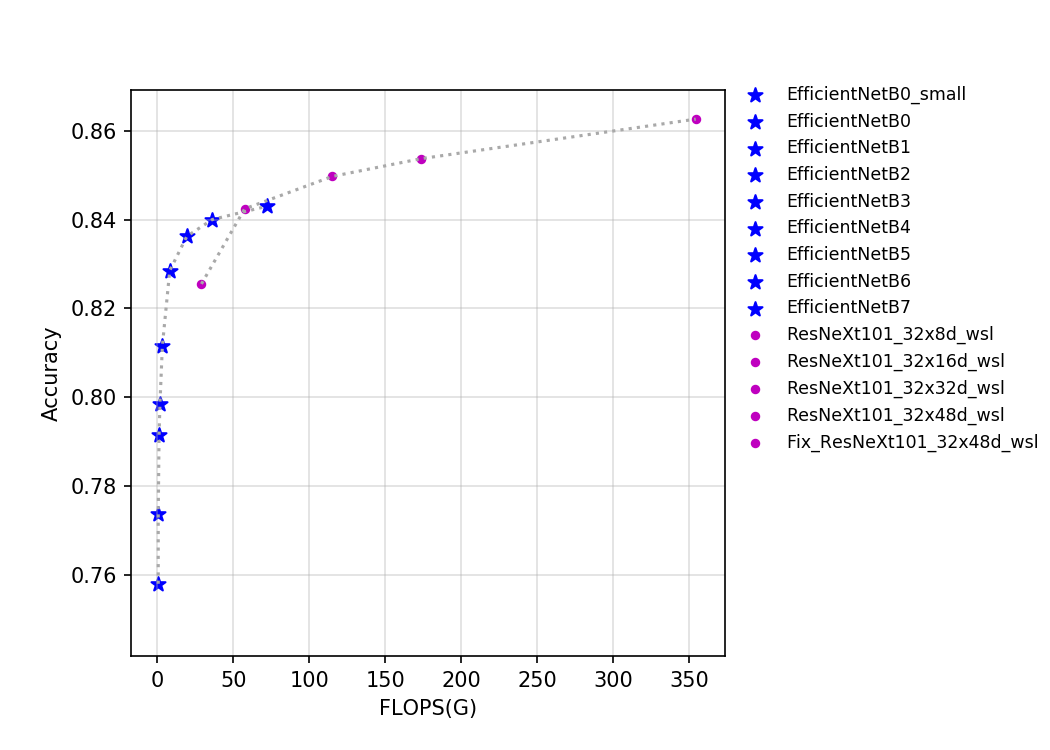
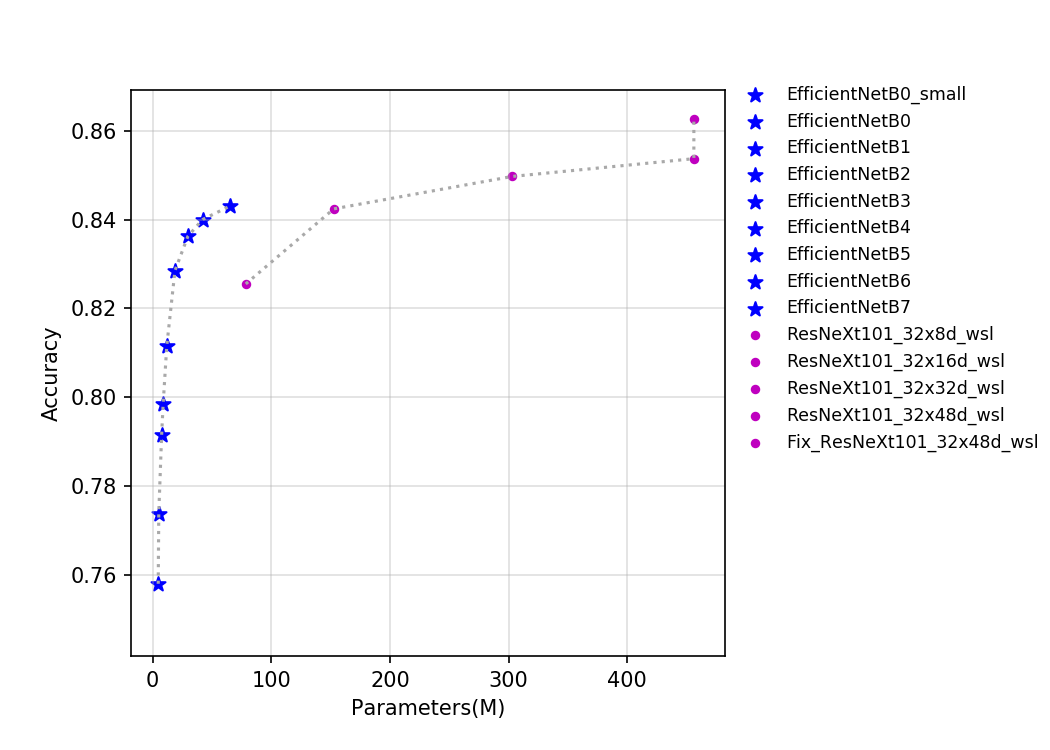
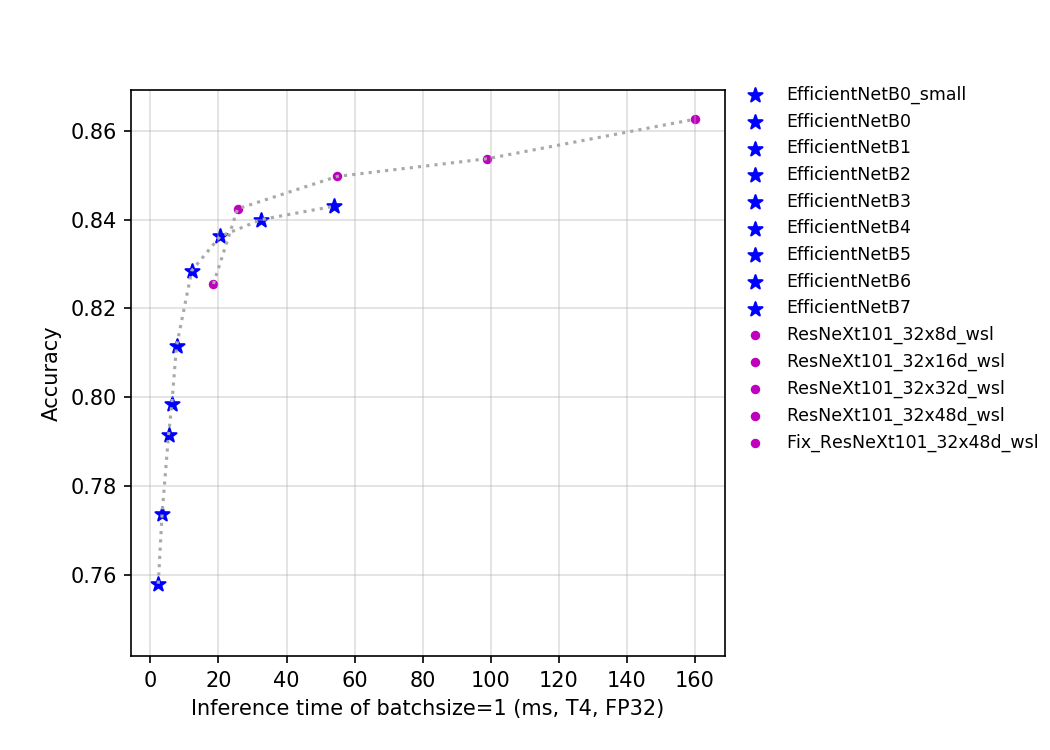
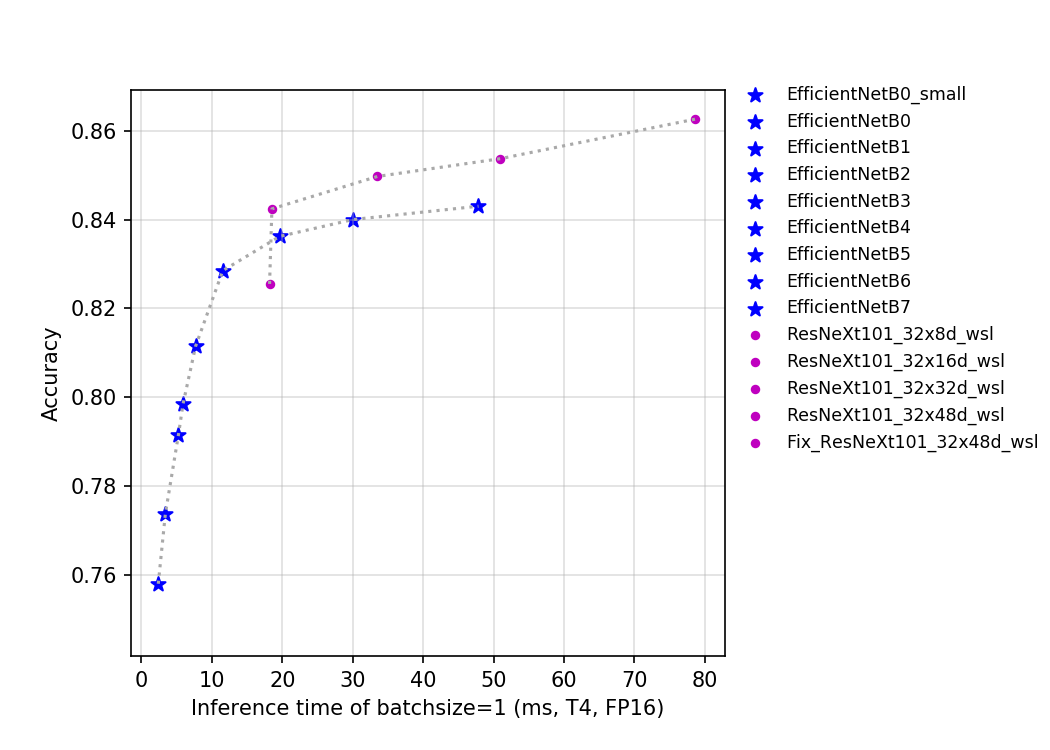
目前PaddleClas开源的这两类模型的预训练模型一共有14个。从上图中可以看出EfficientNet系列网络优势非常明显,ResNeXt101_wsl系列模型由于用到了更多的数据,最终的精度也更高。EfficientNet_B0_Small是去掉了SE_block的EfficientNet_B0,其具有更快的推理速度。
精度、FLOPS和参数量¶
| Models | Top1 | Top5 | Reference top1 |
Reference top5 |
FLOPS (G) |
Parameters (M) |
|---|---|---|---|---|---|---|
| ResNeXt101_ 32x8d_wsl |
0.826 | 0.967 | 0.822 | 0.964 | 29.140 | 78.440 |
| ResNeXt101_ 32x16d_wsl |
0.842 | 0.973 | 0.842 | 0.972 | 57.550 | 152.660 |
| ResNeXt101_ 32x32d_wsl |
0.850 | 0.976 | 0.851 | 0.975 | 115.170 | 303.110 |
| ResNeXt101_ 32x48d_wsl |
0.854 | 0.977 | 0.854 | 0.976 | 173.580 | 456.200 |
| Fix_ResNeXt101_ 32x48d_wsl |
0.863 | 0.980 | 0.864 | 0.980 | 354.230 | 456.200 |
| EfficientNetB0 | 0.774 | 0.933 | 0.773 | 0.935 | 0.720 | 5.100 |
| EfficientNetB1 | 0.792 | 0.944 | 0.792 | 0.945 | 1.270 | 7.520 |
| EfficientNetB2 | 0.799 | 0.947 | 0.803 | 0.950 | 1.850 | 8.810 |
| EfficientNetB3 | 0.812 | 0.954 | 0.817 | 0.956 | 3.430 | 11.840 |
| EfficientNetB4 | 0.829 | 0.962 | 0.830 | 0.963 | 8.290 | 18.760 |
| EfficientNetB5 | 0.836 | 0.967 | 0.837 | 0.967 | 19.510 | 29.610 |
| EfficientNetB6 | 0.840 | 0.969 | 0.842 | 0.968 | 36.270 | 42.000 |
| EfficientNetB7 | 0.843 | 0.969 | 0.844 | 0.971 | 72.350 | 64.920 |
| EfficientNetB0_ small |
0.758 | 0.926 | 0.720 | 4.650 |
基于V100 GPU的预测速度¶
| Models | Crop Size | Resize Short Size | FP32 Batch Size=1 (ms) |
|---|---|---|---|
| ResNeXt101_ 32x8d_wsl |
224 | 256 | 19.127 |
| ResNeXt101_ 32x16d_wsl |
224 | 256 | 23.629 |
| ResNeXt101_ 32x32d_wsl |
224 | 256 | 40.214 |
| ResNeXt101_ 32x48d_wsl |
224 | 256 | 59.714 |
| Fix_ResNeXt101_ 32x48d_wsl |
320 | 320 | 82.431 |
| EfficientNetB0 | 224 | 256 | 2.449 |
| EfficientNetB1 | 240 | 272 | 3.547 |
| EfficientNetB2 | 260 | 292 | 3.908 |
| EfficientNetB3 | 300 | 332 | 5.145 |
| EfficientNetB4 | 380 | 412 | 7.609 |
| EfficientNetB5 | 456 | 488 | 12.078 |
| EfficientNetB6 | 528 | 560 | 18.381 |
| EfficientNetB7 | 600 | 632 | 27.817 |
| EfficientNetB0_ small |
224 | 256 | 1.692 |
基于T4 GPU的预测速度¶
| Models | Crop Size | Resize Short Size | FP16 Batch Size=1 (ms) |
FP16 Batch Size=4 (ms) |
FP16 Batch Size=8 (ms) |
FP32 Batch Size=1 (ms) |
FP32 Batch Size=4 (ms) |
FP32 Batch Size=8 (ms) |
|---|---|---|---|---|---|---|---|---|
| ResNeXt101_ 32x8d_wsl |
224 | 256 | 18.19374 | 21.93529 | 34.67802 | 18.52528 | 34.25319 | 67.2283 |
| ResNeXt101_ 32x16d_wsl |
224 | 256 | 18.52609 | 36.8288 | 62.79947 | 25.60395 | 71.88384 | 137.62327 |
| ResNeXt101_ 32x32d_wsl |
224 | 256 | 33.51391 | 70.09682 | 125.81884 | 54.87396 | 160.04337 | 316.17718 |
| ResNeXt101_ 32x48d_wsl |
224 | 256 | 50.97681 | 137.60926 | 190.82628 | 99.01698256 | 315.91261 | 551.83695 |
| Fix_ResNeXt101_ 32x48d_wsl |
320 | 320 | 78.62869 | 191.76039 | 317.15436 | 160.0838242 | 595.99296 | 1151.47384 |
| EfficientNetB0 | 224 | 256 | 3.40122 | 5.95851 | 9.10801 | 3.442 | 6.11476 | 9.3304 |
| EfficientNetB1 | 240 | 272 | 5.25172 | 9.10233 | 14.11319 | 5.3322 | 9.41795 | 14.60388 |
| EfficientNetB2 | 260 | 292 | 5.91052 | 10.5898 | 17.38106 | 6.29351 | 10.95702 | 17.75308 |
| EfficientNetB3 | 300 | 332 | 7.69582 | 16.02548 | 27.4447 | 7.67749 | 16.53288 | 28.5939 |
| EfficientNetB4 | 380 | 412 | 11.55585 | 29.44261 | 53.97363 | 12.15894 | 30.94567 | 57.38511 |
| EfficientNetB5 | 456 | 488 | 19.63083 | 56.52299 | - | 20.48571 | 61.60252 | - |
| EfficientNetB6 | 528 | 560 | 30.05911 | - | - | 32.62402 | - | - |
| EfficientNetB7 | 600 | 632 | 47.86087 | - | - | 53.93823 | - | - |
| EfficientNetB0_small | 224 | 256 | 2.39166 | 4.36748 | 6.96002 | 2.3076 | 4.71886 | 7.21888 |