模型库概览¶
概述¶
基于ImageNet1k分类数据集,PaddleClas支持的23种系列分类网络结构以及对应的117个图像分类预训练模型如下所示,训练技巧、每个系列网络结构的简单介绍和性能评估将在相应章节展现。
评估环境¶
- CPU的评估环境基于骁龙855(SD855)。
- GPU评估环境基于V100和TensorRT,评估脚本如下。
#!/usr/bin/env bash
export PYTHONPATH=$PWD:$PYTHONPATH
python tools/infer/predict.py \
--model_file='pretrained/infer/model' \
--params_file='pretrained/infer/params' \
--enable_benchmark=True \
--model_name=ResNet50_vd \
--use_tensorrt=True \
--use_fp16=False \
--batch_size=1
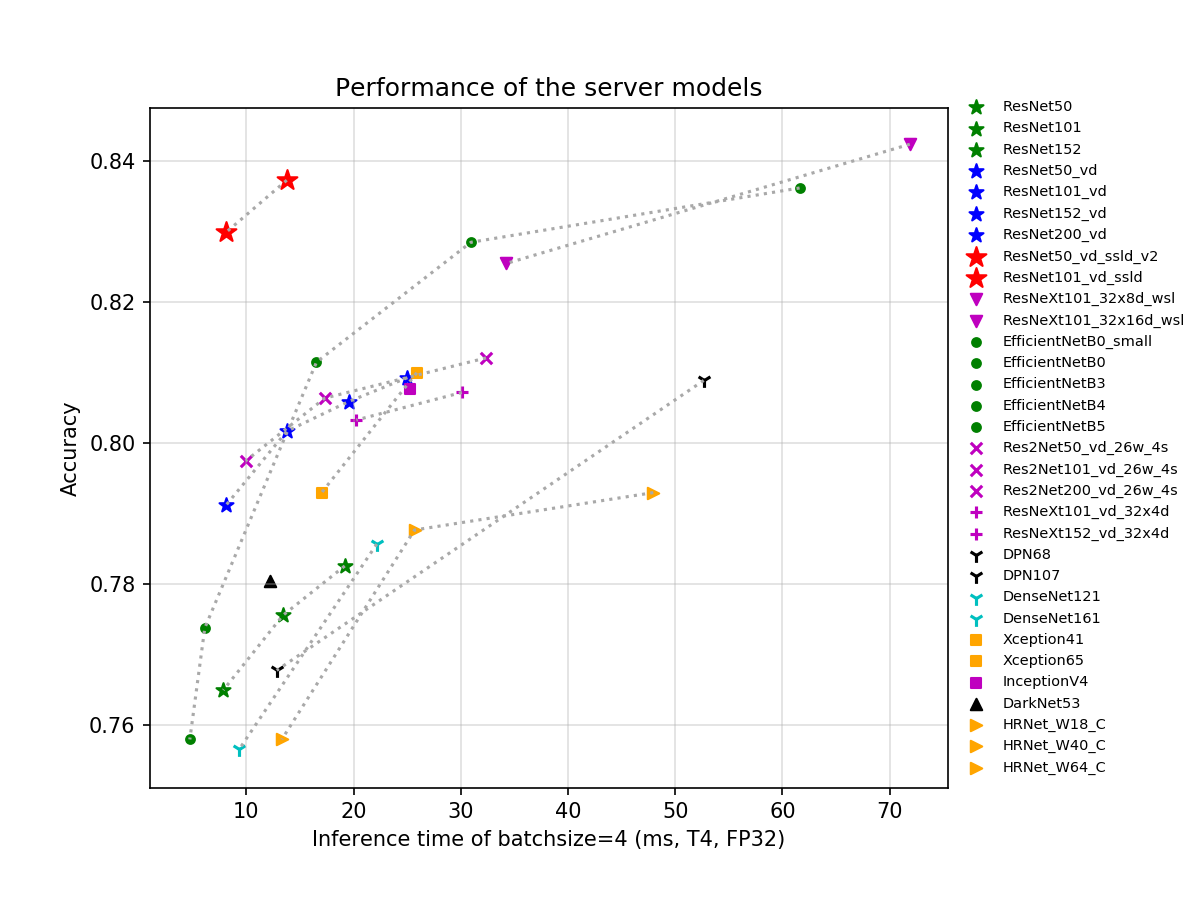
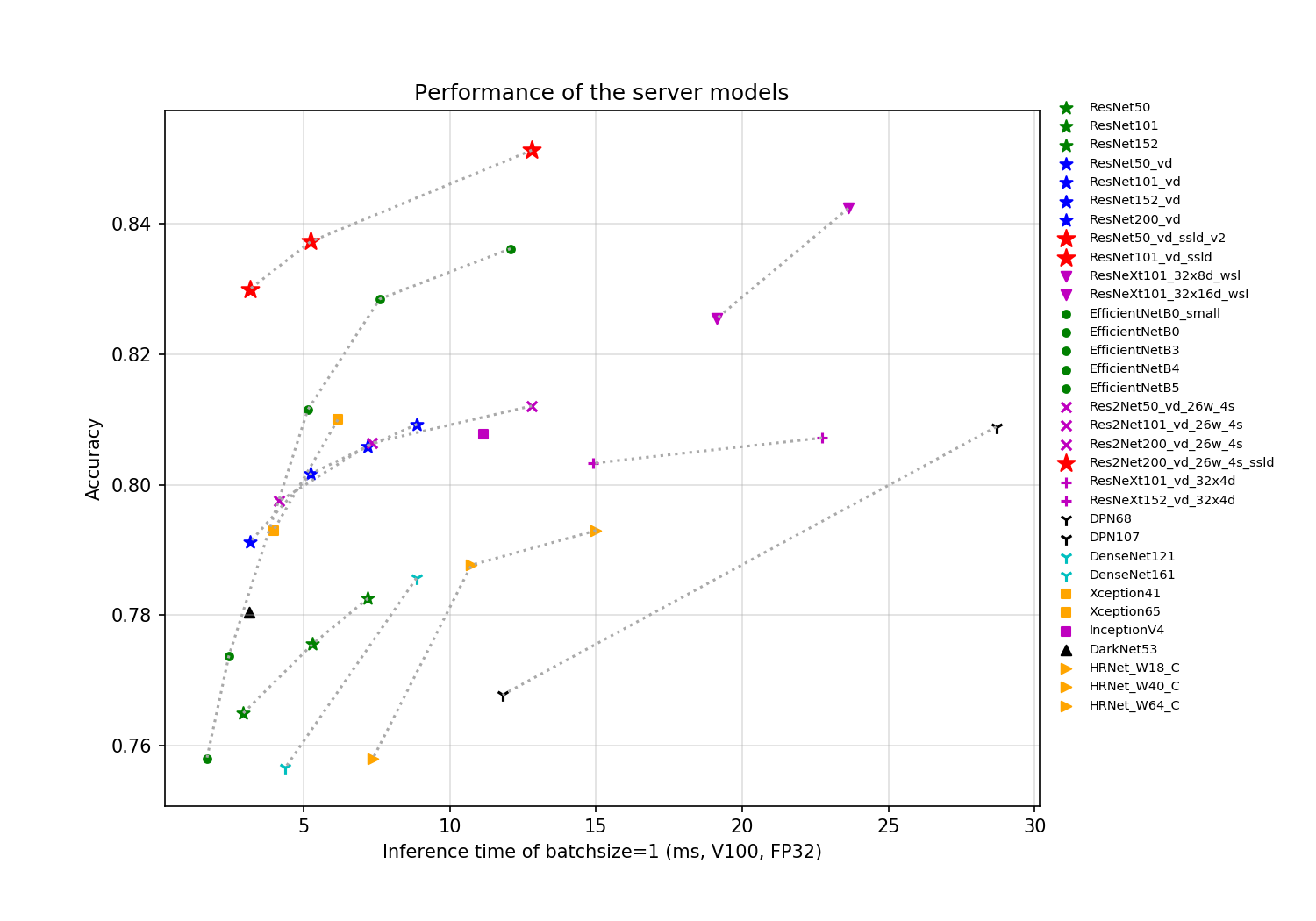
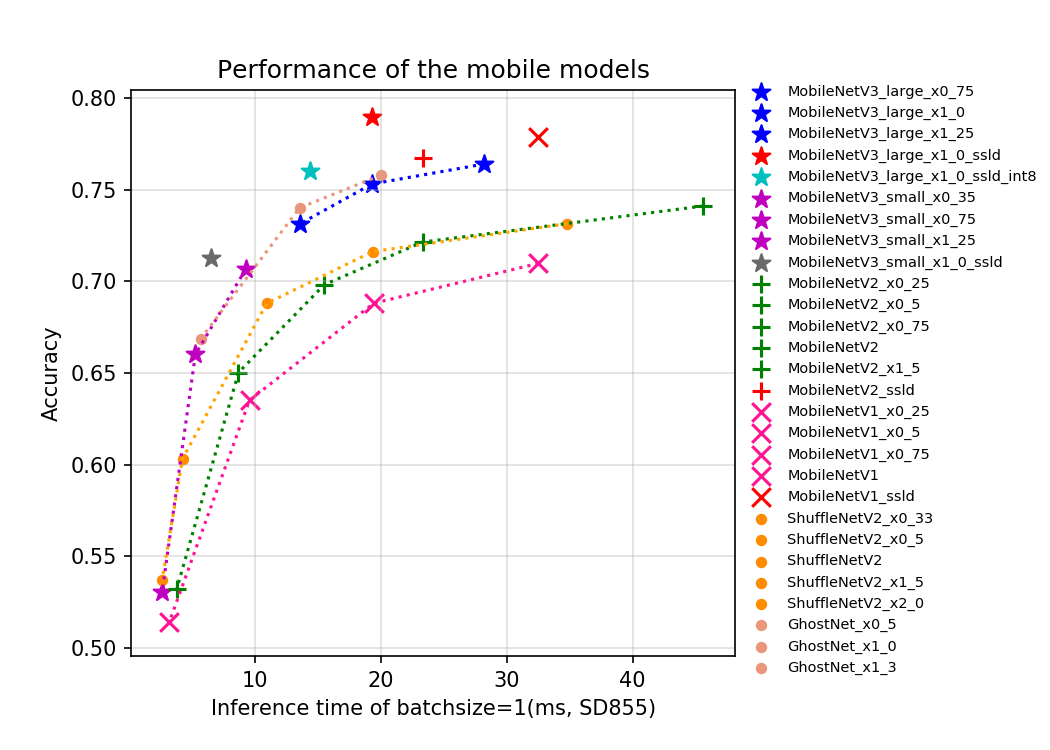
如果您觉得此文档对您有帮助,欢迎star我们的项目:https://github.com/PaddlePaddle/PaddleClas
预训练模型列表及下载地址¶
- ResNet及其Vd系列
- 移动端系列
- MobileNetV3系列[3](论文地址)
- MobileNetV3_large_x0_35
- MobileNetV3_large_x0_5
- MobileNetV3_large_x0_75
- MobileNetV3_large_x1_0
- MobileNetV3_large_x1_25
- MobileNetV3_small_x0_35
- MobileNetV3_small_x0_5
- MobileNetV3_small_x0_75
- MobileNetV3_small_x1_0
- MobileNetV3_small_x1_25
- MobileNetV3_large_x1_0_ssld
- MobileNetV3_large_x1_0_ssld_int8
- MobileNetV3_small_x1_0_ssld
- MobileNetV2系列[4](论文地址)
- MobileNetV1系列[5](论文地址)
- ShuffleNetV2系列[6](论文地址)
- GhostNet系列[23](论文地址)
- MobileNetV3系列[3](论文地址)
- SEResNeXt与Res2Net系列
- Inception系列
- HRNet系列
- DPN与DenseNet系列
- EfficientNet与ResNeXt101_wsl系列
- 其他模型
注意:以上模型中EfficientNetB1-B7的预训练模型转自pytorch版EfficientNet,ResNeXt101_wsl系列预训练模型转自官方repo,剩余预训练模型均基于飞浆训练得到的,并在configs里给出了相应的训练超参数。
参考文献¶
[1] He K, Zhang X, Ren S, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 770-778.
[2] He T, Zhang Z, Zhang H, et al. Bag of tricks for image classification with convolutional neural networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019: 558-567.
[3] Howard A, Sandler M, Chu G, et al. Searching for mobilenetv3[C]//Proceedings of the IEEE International Conference on Computer Vision. 2019: 1314-1324.
[4] Sandler M, Howard A, Zhu M, et al. Mobilenetv2: Inverted residuals and linear bottlenecks[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 4510-4520.
[5] Howard A G, Zhu M, Chen B, et al. Mobilenets: Efficient convolutional neural networks for mobile vision applications[J]. arXiv preprint arXiv:1704.04861, 2017.
[6] Ma N, Zhang X, Zheng H T, et al. Shufflenet v2: Practical guidelines for efficient cnn architecture design[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018: 116-131.
[7] Xie S, Girshick R, Dollár P, et al. Aggregated residual transformations for deep neural networks[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 1492-1500.
[8] Hu J, Shen L, Sun G. Squeeze-and-excitation networks[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 7132-7141.
[9] Gao S, Cheng M M, Zhao K, et al. Res2net: A new multi-scale backbone architecture[J]. IEEE transactions on pattern analysis and machine intelligence, 2019.
[10] Szegedy C, Liu W, Jia Y, et al. Going deeper with convolutions[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2015: 1-9.
[11] Szegedy C, Ioffe S, Vanhoucke V, et al. Inception-v4, inception-resnet and the impact of residual connections on learning[C]//Thirty-first AAAI conference on artificial intelligence. 2017.
[12] Chollet F. Xception: Deep learning with depthwise separable convolutions[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 1251-1258.
[13] Wang J, Sun K, Cheng T, et al. Deep high-resolution representation learning for visual recognition[J]. arXiv preprint arXiv:1908.07919, 2019.
[14] Chen Y, Li J, Xiao H, et al. Dual path networks[C]//Advances in neural information processing systems. 2017: 4467-4475.
[15] Huang G, Liu Z, Van Der Maaten L, et al. Densely connected convolutional networks[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 4700-4708.
[16] Tan M, Le Q V. Efficientnet: Rethinking model scaling for convolutional neural networks[J]. arXiv preprint arXiv:1905.11946, 2019.
[17] Mahajan D, Girshick R, Ramanathan V, et al. Exploring the limits of weakly supervised pretraining[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018: 181-196.
[18] Krizhevsky A, Sutskever I, Hinton G E. Imagenet classification with deep convolutional neural networks[C]//Advances in neural information processing systems. 2012: 1097-1105.
[19] Iandola F N, Han S, Moskewicz M W, et al. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and< 0.5 MB model size[J]. arXiv preprint arXiv:1602.07360, 2016.
[20] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition[J]. arXiv preprint arXiv:1409.1556, 2014.
[21] Redmon J, Divvala S, Girshick R, et al. You only look once: Unified, real-time object detection[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 779-788.
[22] Ding X, Guo Y, Ding G, et al. Acnet: Strengthening the kernel skeletons for powerful cnn via asymmetric convolution blocks[C]//Proceedings of the IEEE International Conference on Computer Vision. 2019: 1911-1920.
[23] Han K, Wang Y, Tian Q, et al. GhostNet: More features from cheap operations[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 1580-1589.